前端-缓存
什么是缓存
缓存是计算机内存中的一块特殊区域,用于临时存储经常使用或频繁访问的数据,以减少对原始数据源的访问次数,提高程序性能和响应速度。缓存的存在可以减少IO操作,提高数据读取速度,同时减轻服务器的负载。
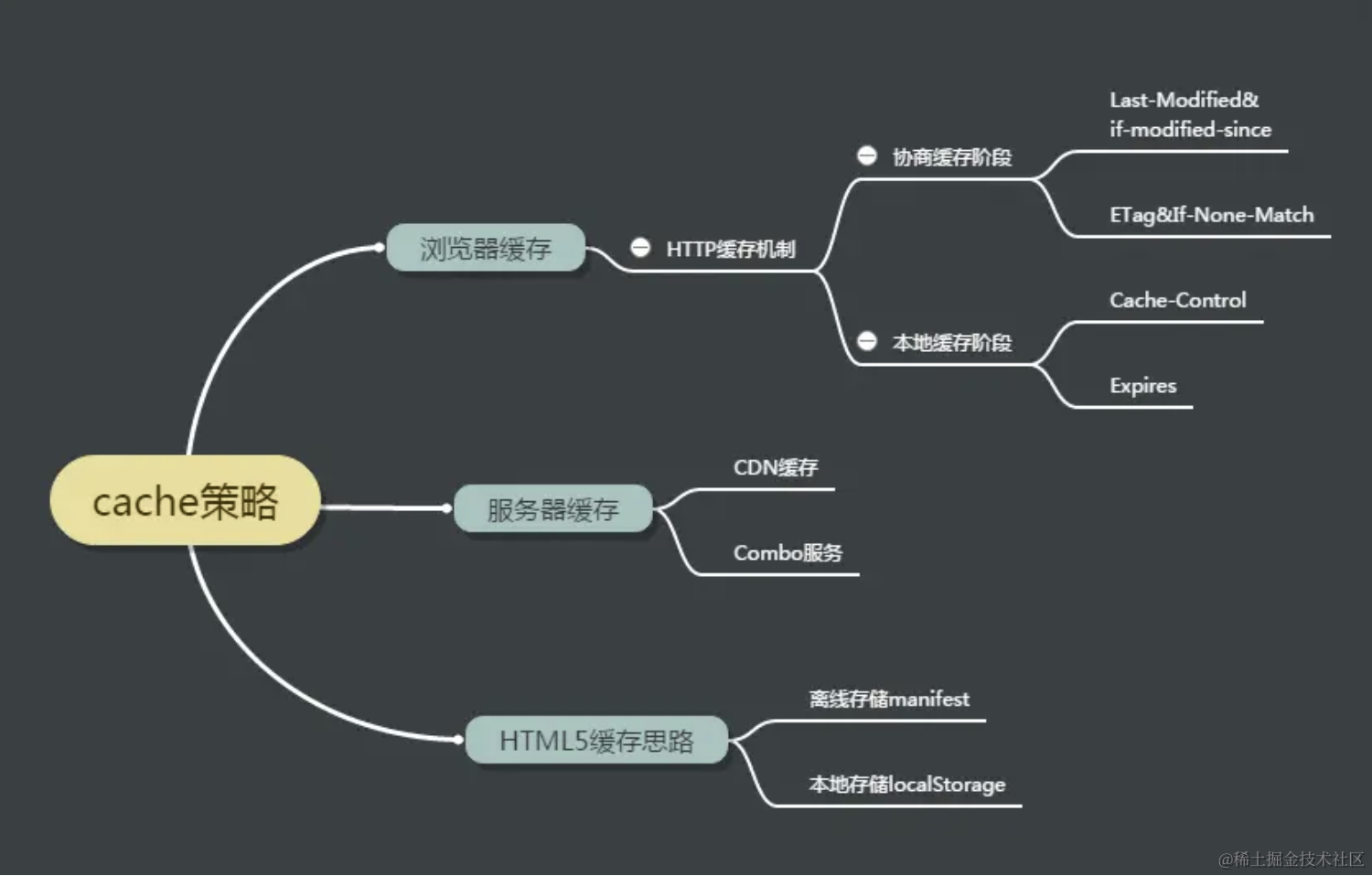
缓存策略 图片来源:IMWeb前端
缓存的作用
- 减少网络带宽消耗
- 降低服务器压力
- 减少网络延迟,加快页面打开速度
哪些地资源可以被缓存(js css img)
浏览器的缓存
浏览器缓存机制是什么?
浏览器缓存机制是指浏览器在用户访问网页时,根据一定的规则和策略,将网页资源(如HTML、CSS、JavaScript、图片等)缓存在本地,以便在用户再次访问该网页时,直接从缓存中读取资源,而不需要重新从服务器下载。
请简述浏览器如何判断是否使用缓存?
浏览器通过比较请求的URL和缓存中是否有相同的URL来确定是否使用缓存。如果缓存中有相同的URL,则浏览器会直接从缓存中读取资源;否则,浏览器会向服务器发送请求获取新的资源。
请简述浏览器强制刷新页面和清除缓存的快捷键是什么?
在大多数浏览器中,强制刷新页面的快捷键是Ctrl + F5或Cmd + Shift + R(Mac),清除缓存的快捷键是Ctrl + Shift + R(Windows)或Cmd + Shift + R(Mac)
请简述浏览器如何更新缓存中的资源?
浏览器通过设置HTTP响应头中的Cache-Control和Last-Modified属性来控制缓存资源的更新。当浏览器再次访问某个资源时,会向服务器发送请求,携带Last-Modified属性,服务器会根据Last-Modified属性判断资源是否被修改,如果没有被修改,则返回304 Not Modified状态码,告诉浏览器从缓存中读取;否则,服务器返回新的资源
http缓存
http分为强缓存和协商缓存
请简述HTTP缓存机制
HTTP缓存机制则是指在HTTP请求和响应中使用的缓存机制。当浏览器向服务器发送HTTP请求时,服务器会在响应头中包含一些缓存控制指令,如Expires、Cache-Control等。这些指令告诉浏览器如何缓存响应中的资源。浏览器会根据这些指令将资源缓存在本地,并在后续请求中直接使用缓存的资源,而不是重新向服务器发送请求。这种缓存机制可以减少网络传输的数据量,提高网页的加载速度
强缓存
Response Headers 中 服务器来设置的
Cache-Control
第一次请求后台设置了response Headers中Cache-Control
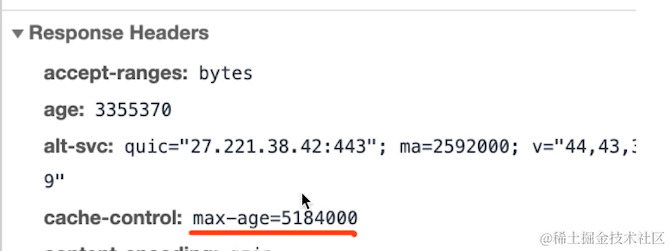
第二次前端再次请求浏览器只要看到Cache-Control这个时间没有过期,浏览器就不会请求而是从缓存里取
如何再请求发现已经过期了那就会请求后台资源,后台会重新再次设置缓存时间Cache-Control
Cache-Control的值
max-age 最大过期时间
no-cache 不用本地缓存正常去服务端请求
no-store 不用本地缓存不用服务端缓存
private 最终用户做缓存
public 允许中间代理做缓存
Expires
同在Response Headers中,同为控制缓存过期,已被Cache-Control代替
协商缓存(对比缓存)
- 服务器端缓存策略
就是一个资源到了服务端,服务端可以告诉前端这个资源没有变化可以使用缓存(并不是服务端缓存) - 服务器判断客户端资源,是否和服务端资源一样
- 一致则返回304,否则返回200和最新的资源
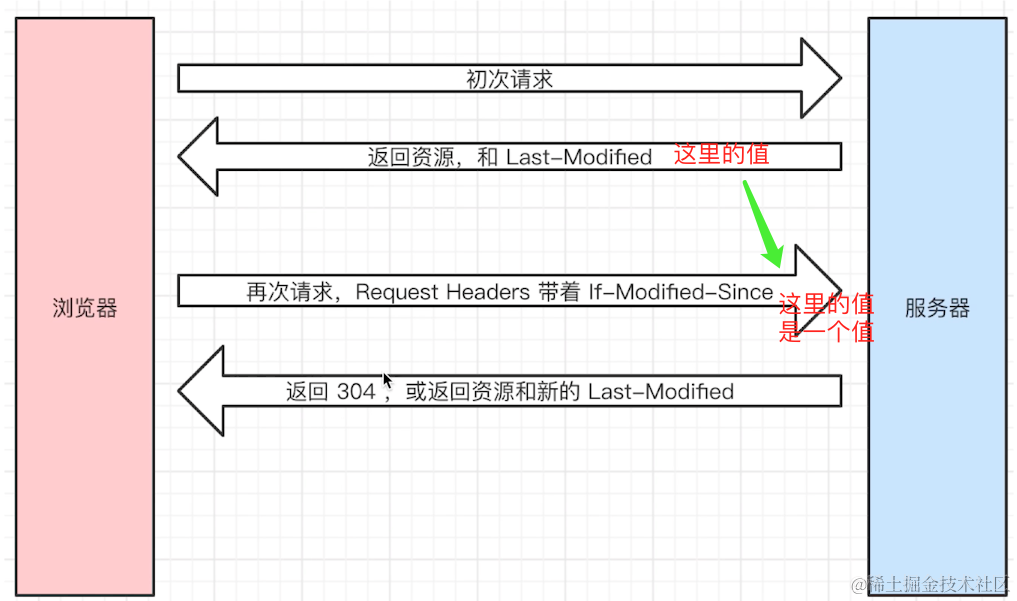
Etag
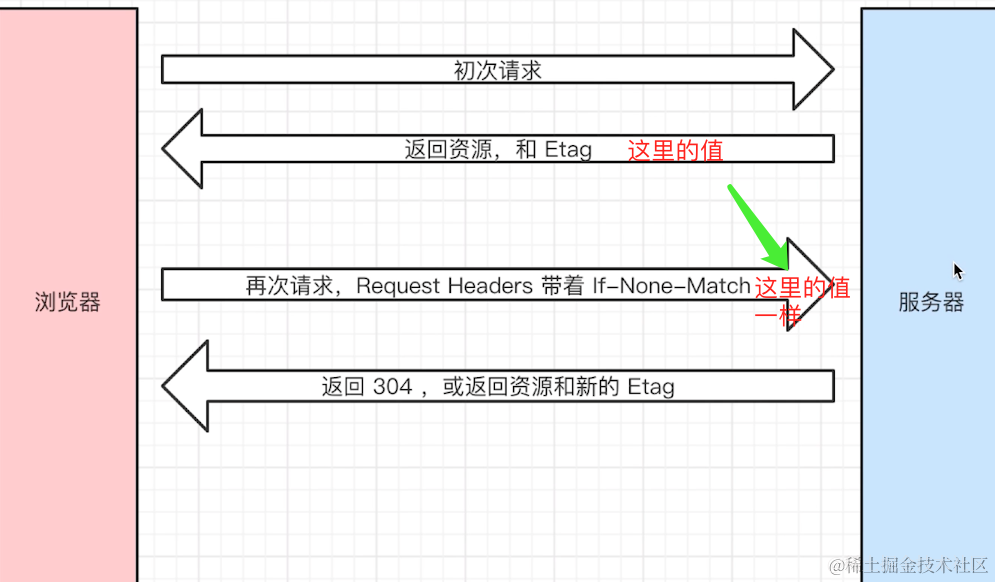
事例:

如果last-modified 和Etag 同时存在以Etag为准
- 会优先使用Etag
- Last-Modified只能精确到秒级
- 如果资源被重复生成,而内容不变,则Etag更精确

图片来源双越老师
状态码
HTTP协议的状态码有很多种,下面是常见的一些状态码:
- 200:OK,请求成功。
- 201:Created,请求成功并且创建了新的资源。
- 202:Accepted,请求成功但是需要继续处理。
- 204:No Content,请求成功,但是资源没有内容。
- 301:Moved Permanently,资源永久性移动。
- 302:Found,资源临时移动。
- 304:Not Modified,资源没有修改。
- 400:Bad Request,请求格式错误。
- 401:Unauthorized,没有权限。
- 403:Forbidden,禁止访问。
- 404:Not Found,请求的资源不存在。
- 405:Method Not Allowed,请求方法不被允许。
- 418:I'm a teapot,服务器拒绝了请求。
- 500:Internal Server Error,服务器内部错误。
- 503:Service Unavailable,服务器暂时不可用。服务器缓存
CDN
HTML5缓存
请简述使用Service Worker实现离线功能的原理和步骤
Service Worker是现代Web应用程序中的一种新API,它允许你在浏览器后台运行脚本,以拦截和处理网络请求,包括程序化缓存。使用Service Worker实现离线功能的基本原理和步骤如下:
基本原理
Service Worker在浏览器启动时运行并监听各种事件,包括网络请求。当用户请求一个页面或资源时,Service Worker可以拦截这个请求并决定返回什么。通过编程缓存(即通过Service Worker的缓存API),你可以在用户离线时从缓存中取出数据。
基本步骤
- 注册 Service Worker:在你的主JavaScript文件中,你需要先注册一个Service Worker。只有当你的网站通过HTTPS协议访问时,才能安全地注册Service Worker。
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/service-worker.js')
.then(function(registration) {
console.log('Service Worker 注册成功');
})
.catch(function(err) {
console.log('Service Worker 注册失败:', err);
});
}- 安装和激活 Service Worker:注册成功后,浏览器会开始下载和安装Service Worker。一旦Service Worker被安装并激活,它就可以开始监听网络请求。
- 缓存资源:你可以使用
caches.open()和caches.put()方法来缓存你的资源。在用户第一次访问你的网站时,Service Worker会拦截网络请求,并从缓存中获取资源。如果缓存中没有,再从网络中获取。
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('my-cache').then(function(cache) {
return cache.addAll([
'/',
'/index.html',
'/app.js',
'/styles.css',
'/image.png'
]);
})
);
});- 在离线时提供缓存的资源:如果用户在离线时尝试访问你的网站,Service Worker会拦截这个请求并从缓存中返回资源。你可以使用
self.fetch()方法来处理网络请求,如果缓存中有匹配的资源,就返回它,否则就调用fetch()来从网络中获取。
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
if (response) {
return response;
}
return fetch(event.request).then(function(response) {
return caches.open('my-cache').then(function(cache) {
cache.put(event.request, response.clone());
return response;
});
});
})
);
});- 更新 Service Worker:如果你需要更新你的Service Worker或缓存的资源,你需要先卸载旧的Service Worker,然后再安装新的。这可以通过调用
navigator.serviceWorker.getRegistration()来实现。
版权声明:本文由Web学习之路发布,如需转载请注明出处。